A Comprehensive Guide to Evaluating LLM-Generated Knowledge Graphs: From PoC to Production
TLDR; Creating Knowledge Graphs using Large Language Models (LLMs) with Graphora is powerful but requires robust evaluation. This guide shows you how to:
- Build a production-ready evaluation pipeline for LLM-driven knowledge graphs
- Implement automated quality checks using LLMs as judges
- Set up comprehensive tracing and monitoring
- Use industry-standard metrics to measure graph quality
- Handle entity resolution and graph integration
Key tools covered: Instructor, LangSmith, Lilac.
Complete implementation available in the accompanying Jupyter notebook.
Target audience: ML Engineers and Data Scientists working on Knowledge Graph creation and maintenance.
Introduction
Creating Knowledge Graphs—structured representations of entities and their relationships—from unstructured data has become increasingly valuable beyond just Graph Retrieval Augmented Generation (GraphRAG). While Large Language Models (LLMs) have simplified this process, the critical step of evaluation is often overlooked or missing entirely. Drawing inspiration from comprehensive works on Applied LLM evaluations by Hamel Husain and Eugene Yan, this article provides a practical guide for evaluating your LLM-driven Knowledge Graph creation process.
With this foundation in mind, let's explore how to build these knowledge graphs efficiently, particularly using modern LLM approaches.
High-Level Architecture
Before diving into implementation details, let's understand the overall architecture of our LLM-driven Knowledge Graph evaluation pipeline. Here is the accompanying Jupyter notebook.
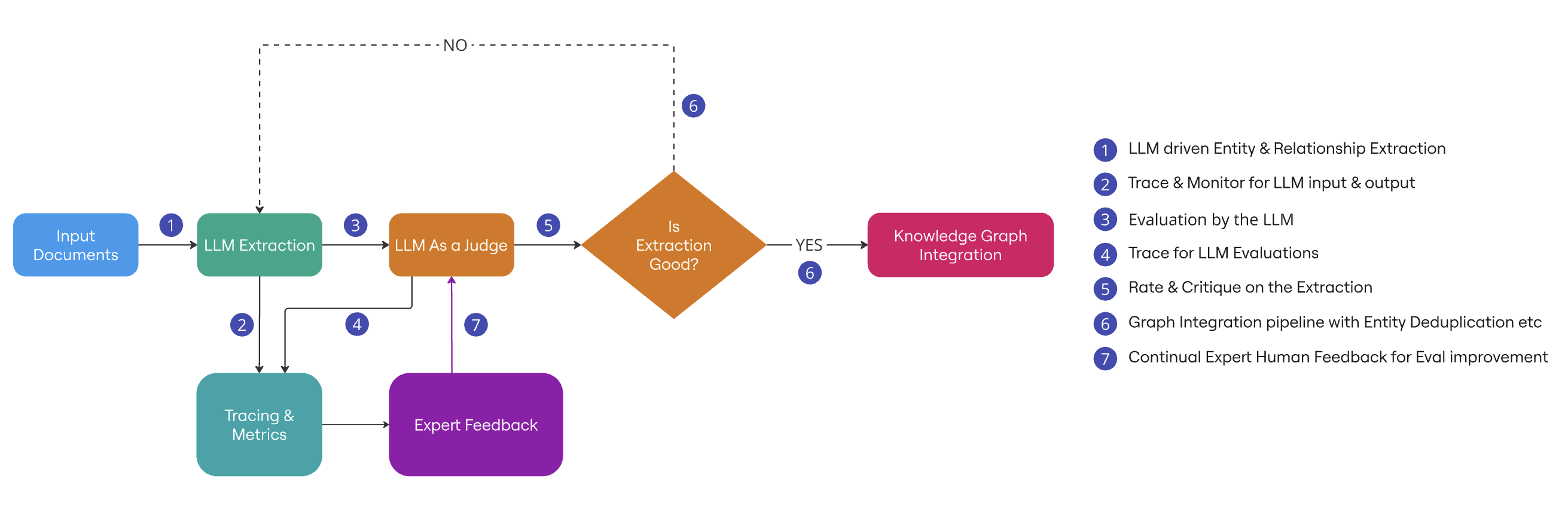
Building Knowledge Graphs
Processing unstructured data as graphs offers significant advantages, particularly in quick traversal and insight generation from connected information. Consider fraud detection: by analyzing a person's connections and associations derived from social media posts, news events, and transaction logs, a graph-based system can assess fraud risk in a low latency manner.
While traditionally building such graphs required substantial time and expertise, LLMs can accelerate this process through three main approaches:
- Domain-specific Ontology Extraction: Using predefined rules and relationships to structure information
- Hierarchical Text Chunk Extraction: Breaking down and storing information as connected, vectorized chunks
- Hybrid Approach: Combining ontology-driven structure with flexible text extraction
The ontology-driven approach, though requiring initial investment in taxonomy development, provides precise control. However, building the graph is only half the battle - ensuring its quality and reliability is equally crucial.
Why Evals?
Regardless of your chosen graph-building approach, robust evaluation is crucial—similar to writing test cases for software applications. This evaluation serves multiple critical purposes:
Quality Assurance:
- Ensures correctness, factuality, semantic accuracy, and knowledge completeness
- Validates proper handling of sensitive and Personally Identifiable Information (PII) in regulated industries
- Verifies compliance with ontology rules for cleaner, more reliable data
Risk Mitigation:
- Prevents costly errors from incorrect graph relationships
- Reduces negative impacts on downstream applications
- Protects against data drift and model decay
With the rapid pace of model releases and updates, implementing thorough evaluation processes becomes critical. To move from theory to practice, let's explore these concepts through a concrete example.
Evaluating your Graph: A Real-World Example
Let's apply these evaluation concepts to a practical use case: building a Knowledge Graph from Securities and Exchange Commission (SEC) Form 10K Annual reports. We'll focus specifically on Part I of Form 10-K, with particular emphasis on the Business section.

For context, Form 10-K is a comprehensive report mandated by the SEC that provides a complete summary of a company's financial performance. Part I of Form 10-K contains critical narrative information including:
- Business Overview - Company operations and primary activities - Revenue streams and business model - Market presence and competition - Key products and services
- Risk Factors
- Properties
- Legal Proceedings
- Mine Safety Disclosures (if applicable)
We'll concentrate on the Business section as it provides rich, structured information about a company's operations, making it an ideal candidate for knowledge graph creation. To effectively capture this information, we need a well-defined structure for our graph.
Building Knowledge Graphs with Domain-Specific Ontologies
Knowledge graph creation begins with defining clear rules for entity extraction and relationships. This process typically involves collaboration with Subject Matter Experts (SMEs) who understand both the domain (in our case, financial documents) and the specific information we need to capture.
For our Form 10-K Part I analysis, we'll use a Pydantic-based ontology structure. While other formats like RDF, Turtle, or JSON-LD are equally valid, Pydantic offers several advantages:
- Type safety and validation
- Easy integration with Python ecosystems
- Clear, maintainable code structure
- IDE support for better development experience
Here's our ontology definition:
1class Business(BaseModel): 2 """Item 1: Business description and operations""" 3 id: str = Field(..., description="Unique identifier for the business section") 4 description: str = Field(..., description="General description of the business") 5 segments: List[str] = Field(default_factory=list, description="List of Business segments. Do no club segments together") 6 products: List[str] = Field(default_factory=list, description="List of Main products and services") 7 competition: str = Field(..., description="Competitive environment description") 8 raw_materials: Optional[str] = Field(None, description="Description of raw materials used") 9 intellectual_property: Optional[str] = Field(None, description="IP rights and portfolio") 10 seasonality: Optional[str] = Field(None, description="Business seasonality patterns") 11 employees: Optional[int] = Field(None, description="Number of employees") 12 regulatory_environment: Optional[str] = Field(None, description="Regulatory framework description")13
14class RiskFactor(BaseModel): 15 """Item 1A: Risk Factors""" 16 id: str = Field(..., description="Unique identifier for the risk factor") 17 risk_category: str = Field(..., description="Category of the risk") 18 risk_description: str = Field(..., description="Detailed description of the risk") 19 potential_impact: str = Field(..., description="Potential impact on business") 20 mitigation_strategy: Optional[str] = Field(None, description="Risk mitigation strategy")21
22class Property(BaseModel): 23 """Item 2: Properties""" 24 id: str = Field(..., description="Unique identifier for the property") 25 location: str = Field(..., description="Property location") 26 property_type: str = Field(..., description="Type of property (Owned/Leased)") 27 square_footage: Optional[float] = Field(None, description="Property size in square feet") 28 primary_use: str = Field(..., description="Primary use of the property") 29 expiration_date: Optional[date] = Field(None, description="Lease expiration date if applicable")30
31class LegalProceeding(BaseModel): 32 """Item 3: Legal Proceedings""" 33 id: str = Field(..., description="Unique identifier for the legal proceeding") 34 case_description: str = Field(..., description="Description of the legal case") 35 jurisdiction: str = Field(..., description="Legal jurisdiction") 36 status: str = Field(..., description="Current status of the proceeding") 37 potential_liability: Optional[float] = Field(None, description="Potential financial liability") 38 expected_resolution: Optional[str] = Field(None, description="Expected resolution timeline")39
40class MineSafety(BaseModel): 41 """Item 4: Mine Safety Disclosures""" 42 id: str = Field(..., description="Unique identifier for mine safety record") 43 violations: Optional[int] = Field(None, description="Number of safety violations") 44 citations: List[str] = Field(default_factory=list, description="Safety citations received") 45 assessments: Optional[float] = Field(None, description="Financial assessments or penalties")46
47class PartI(BaseModel): 48 """Part I of Form 10-K""" 49 id: str = Field(..., description="Unique identifier for Part I") 50 business: Business = Field(..., description="Item 1: Business") 51 risk_factors: List[RiskFactor] = Field(default_factory=list, description="Item 1A: Risk Factors") 52 properties: List[Property] = Field(default_factory=list, description="Item 2: Properties") 53 legal_proceedings: List[LegalProceeding] = Field(default_factory=list, description="Item 3: Legal Proceedings") 54 mine_safety: Optional[MineSafety] = Field(None, description="Item 4: Mine Safety Disclosures")55
56class Form10K(BaseModel): 57 """Form 10-K Document""" 58 id: str = Field(..., description="Unique identifier for the Form 10-K") 59 fiscal_year: int = Field(..., description="Fiscal year of the report") 60 filing_date: date = Field(..., description="Date the form was filed") 61 company_name: str = Field(..., description="Name of the company") 62 cik: str = Field(..., description="Central Index Key (CIK) number") 63 part_i: PartI = Field(..., description="Part I of Form 10-K")Developing Evaluation Data
In our case, Form 10-K reports provide an excellent source of training and evaluation data due to their:
- Standardized structure
- Rich business information
- Public availability
- Consistent formatting
However, if you're working with limited data or need to test edge cases, synthetic data generation using LLMs can be valuable. The Instructor library by Jason Liu provides an elegant solution for this:
- Enforces ontology constraints during generation
- Maintains data consistency
- Simplifies prompt engineering
Implementation example:
1import instructor 2from anthropic import Anthropic 3from langsmith import wrappers, traceable4
5# Set up the client with prompt caching 6client = instructor.from_anthropic(Anthropic())7
8@traceable(run_type="llm") 9def extract_form10k_part1(all_form10k): 10 results = [] 11 for content in all_form10k[0:3]: 12 resp, completion = client.chat.completions.create_with_completion( 13 model="claude-3-5-haiku-20241022", 14 messages=[ 15 { 16 "role": "user", 17 "content": [ 18 { 19 "type": "text", 20 "text": "<Form10K-PART-1>" + content + "</Form10K-PART-1>" 21 }, 22 { 23 "type": "text", 24 "text": "Extract Form 10K from the Part I text given above", 25 }, 26 ], 27 }, 28 ], 29 response_model=Form10K, 30 max_tokens=4000, 31 ) 32 results.append((resp, completion, content)) 33 return results34
35results = extract_form10k_part1(all_form10k)This approach generates structured outputs like:
1Form10K(id='AE-2023-10K', fiscal_year=2023, filing_date=datetime.date(2024, 2, 29), company_name='Adams Resources & Energy, Inc.', cik='0000032945', part_i=PartI(id='PART-I-2023', business=Business(id='AE-BUSINESS-2023', description='Adams Resources & Energy, Inc. is a publicly traded Delaware corporation organized in 1973. Through its subsidiaries, the company is primarily engaged in crude oil marketing, truck and pipeline transportation of crude oil, terminalling and storage in various crude oil and natural gas basins in the lower 48 states of the United States. The company also conducts tank truck transportation of liquid chemicals, pressurized gases, asphalt and dry bulk, and recycles and repurposes off-specification fuels, lubricants, crude oil and other chemicals from producers in the U.S.', segments=['crude oil marketing, transportation and storage', 'tank truck transportation of liquid chemicals, pressurized gases, asphalt and dry bulk', 'pipeline transportation, terminalling and storage of crude oil', 'interstate bulk transportation logistics of crude oil, condensate, fuels, oils and other petroleum products and recycling and repurposing of off-specification fuels, lubricants, crude oil and other chemicals'], products=['Crude oil marketing', 'Truck transportation services', 'Pipeline transportation', 'Chemical and fuel recycling'], competition='Strong competition from regional and national entities with significant financial resources and more expansive geographic footprints. Competition is primarily in establishing trade credit, pricing, quality of service, and location of service.', raw_materials=None, intellectual_property=None, seasonality='Trucking revenue historically follows seasonal patterns, with peak freight demand in September, October, and November. Winter months typically have lower freight volumes and higher operating expenses.', employees=741, regulatory_environment='Subject to extensive federal, state, and local regulations including environmental laws, transportation regulations, pipeline safety rules, and emerging climate change legislation.'), risk_factors=[RiskFactor(id='RF-DRIVER-SHORTAGE', risk_category='Operational Risk', risk_description='Difficulty in attracting and retaining qualified truck drivers', potential_impact='Could limit growth, increase compensation costs, and reduce operational efficiency', mitigation_strategy='Competitive wages, benefits, modern equipment, and driver training programs'), RiskFactor(id='RF-CREDIT-RISK', risk_category='Financial Risk', risk_description='Dependence on ability to obtain trade and other credit', potential_impact='Could limit marketing businesses, improvements, and future growth', mitigation_strategy='Evaluating financial strength of counterparties and maintaining credit arrangements')], properties=[Property(id='HQ-PROPERTY', location='17 South Briar Hollow Lane, Suite 100, Houston, Texas 77027', property_type='Leased', square_footage=22197.0, primary_use='Headquarters Office', expiration_date=None)], legal_proceedings=[], mine_safety=None))Development Tips
- Experiment with different chunk sizes for optimal extraction
- Iterate on ontology fragments based on extraction results
- Validate generated data against your original ontology rules
- Keep track of edge cases and common failure modes
Tracing and Monitoring
Tracing is crucial for understanding and improving your knowledge graph creation pipeline. It helps capture not just user queries, but the entire extraction and validation process, enabling continuous improvement. Here's how you can implement effective tracing:
Query and Response Tracking
Tools like LangSmith provide comprehensive tracing capabilities:
- Capture input queries and outputs
- Monitor latency and performance
- Track token usage and costs
- Experiment with different prompts and models
- Store examples for in-context learning
In our code above, tracing is enabled using @traceable annotation:
1from langsmith import wrappers, traceable2
3….4
5@traceable(run_type="llm") 6def extract_form10k_part1(all_form10k): 7….Performance Analysis
Lilac offers powerful analytics capabilities:
- Cluster similar queries for pattern recognition
- Identify common failure modes
- Analyze semantic similarity in responses
- Track data drift over time
- Monitor extraction quality metrics
While tracing and monitoring give us insights into system performance, we still need a reliable way to evaluate the quality of our extractions. This brings us to an innovative approach: using LLMs themselves as evaluation judges.
LLM as Judge: Building Reliable Evaluation Systems
While successful extraction is crucial, a production-ready system requires robust evaluation mechanisms to ensure accuracy and prevent hallucinations. Let's explore how to build a reliable evaluation system using LLMs.
Evaluation Approaches
There are several approaches to evaluate extracted data:
1. Fine-tuned Custom Models
- Trained on domain-specific data
- Optimized for specific evaluation tasks
- Requires significant training data
2. High-Performance LLMs as Judges
- Uses more capable models for evaluation
- More cost-effective than fine-tuning
- Flexible and adaptable to changes
Building a Reliable LLM Judge
The key challenge is ensuring the LLM judge itself is reliable. Based on research from this paper, we implement an iterative alignment process:
1. Initial Evaluation
- Create baseline evaluation prompts
- Gather LLM judgments and rationales
- Document evaluation criteria
2. SME Alignment
- Have domain experts review LLM evaluations
- Compare LLM decisions with expert judgment
- Identify gaps and inconsistencies
3. Prompt Refinement
- Iterate on prompts based on feedback
- Target specific failure modes
- Maintain clear evaluation criteria
Implementation Example:
1JUDGE_PROMPT_FOR_BUSINESS_SECTION = f"""You are a Named Entity & Relationships Extraction evaluator with advanced capabilities to judge if the extraction is good or not. 2You understand the nuances of the Financial Industry - more specifically SEC's Form 10K and Neo4j Knowledge Graph, including what is likely to be most useful from a Graph perspective.3
4Here are some guidelines for evaluating queries: 5- ensure that the extraction is accurate and do so only from the text provided 6- For long text descriptions, try to summarize them and capture only what is necessary from a finance perspective7
8Example evaluations:9
10<examples>11
12<example-1> 13<form10k> 14ITEM 1. BUSINESS 15Overview 16GreenTech Solutions, Inc. ("GreenTech" or the "Company") is a leading provider of renewable energy technologies and sustainable infrastructure solutions. Founded in 1995, we design, manufacture, and install solar power systems, energy storage solutions, and smart grid technologies for residential, commercial, and utility-scale applications. Through continued innovation and strategic expansion, we have established ourselves as a trusted partner in the global transition to sustainable energy. 17Business Operations and Segments 18Our operations are structured to address the diverse needs of the renewable energy market. In the residential sector, we provide comprehensive solar solutions to homeowners through our Residential Solar Solutions division, which handles everything from initial energy assessment to system design, installation, and ongoing monitoring. Our Commercial & Industrial Systems division serves businesses, schools, and industrial facilities with larger-scale solar implementations and energy management solutions tailored to reduce operational costs and achieve sustainability goals. Through our Utility Infrastructure segment, we partner with power utilities to develop and maintain large-scale solar farms and energy storage facilities that feed directly into the power grid. 19Products, Services and Technology 20The backbone of our business consists of integrated solar and energy management solutions. We provide complete solar panel systems supported by our advanced installation methodologies. Our energy storage solutions incorporate cutting-edge battery technology to maximize energy efficiency. The Company's smart energy management software enables real-time monitoring and optimization of energy consumption. We also supply essential grid infrastructure components and provide comprehensive maintenance and monitoring services to ensure optimal system performance. Our technical support team offers 24/7 monitoring and rapid response services to maintain system efficiency and reliability. 21Competition and Market Position 22The renewable energy sector remains highly competitive, characterized by rapid technological advancement and evolving customer needs. We face competition from traditional energy companies that are expanding their renewable energy portfolios, pure-play solar providers, and international manufacturers. Key competitive factors in our market include technology efficiency, price, warranty terms, and installation quality. Major competitors include SunPower Corporation, Tesla, and First Solar, who generally have greater financial resources than us. Despite this competitive landscape, we maintain our market position through technological innovation, superior customer service, and comprehensive solution offerings. 23Raw Materials and Supply Chain Management 24The production and installation of our systems depend on various raw materials and components. Primary materials include silicon wafers, solar glass, aluminum frames, and lithium-ion battery components. We have established strategic relationships with multiple suppliers across Asia and North America to ensure supply chain resilience and maintain competitive pricing. Our diversified supplier base helps mitigate risks associated with supply chain disruptions and geopolitical uncertainties. 25</form10k>26
27<query> 28Form10K(part_i=PartI( 29 id="GTECH_2023_PART1", 30 business=Business( 31 id="GTECH_2023_BUSINESS", 32 description="GreenTech Solutions, Inc. ('GreenTech' or the 'Company') is a leading provider of renewable energy technologies and sustainable infrastructure solutions. Founded in 1995, we design, manufacture, and install solar power systems, energy storage solutions, and smart grid technologies for residential, commercial, and utility-scale applications. Through continued innovation and strategic expansion, we have established ourselves as a trusted partner in the global transition to sustainable energy.", 33 segments=[ 34 "Residential Solar Solutions", 35 "Commercial & Industrial Systems", 36 "Utility Infrastructure" 37 ], 38 products=[ 39 "Solar panel systems", 40 "Energy storage solutions", 41 "Smart energy management software", 42 "Grid infrastructure components", 43 "Maintenance and monitoring services", 44 "24/7 monitoring and rapid response services" 45 ], 46 competition="The renewable energy sector remains highly competitive, characterized by rapid technological advancement and evolving customer needs. We face competition from traditional energy companies that are expanding their renewable energy portfolios, pure-play solar providers, and international manufacturers. Key competitive factors in our market include technology efficiency, price, warranty terms, and installation quality. Major competitors include SunPower Corporation, Tesla, and First Solar, who generally have greater financial resources than us.", 47 raw_materials="Primary materials include silicon wafers, solar glass, aluminum frames, and lithium-ion battery components. We have established strategic relationships with multiple suppliers across Asia and North America to ensure supply chain resilience and maintain competitive pricing. Our diversified supplier base helps mitigate risks associated with supply chain disruptions and geopolitical uncertainties.", 48 intellectual_property=None, # Not mentioned in the provided text 49 seasonality=None, # Not mentioned in the provided text 50 employees=None, # Not mentioned in the provided text 51 regulatory_environment=None # Not mentioned in the provided text 52 ) 53)) 54</query> 55<critique> 56{{ 57 "critique": "Extraction is accurate. Unspecified sections are left out. However, description could have been shorter and simpler", 58 "is_pass": "True" 59}} 60</critique> 61</example-1> 62"""Best Practices for LLM Evaluation
1. Binary Decisions
- Use PASS/FAIL instead of scales
- Reduces ambiguity
- Easier to measure alignment
2. Structured Feedback / Critique
- Require specific rationales
- Document decision criteria
- Track improvement areas
This is our Evaluation Response Structure:
class LLMEvalResults(BaseModel):
is_pass: bool = Field(..., description="Is Business section extraction is accurate in the Form10K object? i.e Business content represented by Form10K.part_i.business")
critique: str = Field(..., description="Reason why you think the Business section extraction is bad")
This is how we call the prompt:
1llm_evals = [] 2for resp, completion, text in results: 3 eval_res, c = client.chat.completions.create_with_completion( 4 model="claude-3-5-haiku-20241022", 5 messages=[ 6 { 7 "role": "user", 8 "content": [ 9 { 10 "type": "text", 11 "text": "<form10k>" + text + "</form10k>" 12 }, 13 { 14 "type": "text", 15 "text": JUDGE_PROMPT_FOR_BUSINESS_SECTION, 16 }, 17 ], 18 }, 19 ], 20 response_model=LLMEvalResults, 21 max_tokens=1000, 22 ) 23 llm_evals.append((resp, eval_res, completion, text))Alignment Process:
- Data Collection
- Convert evaluations to CSV format
- Include LLM rationales
- Track evaluation metrics
- SME Review
- Expert validation of results
- Critique of LLM reasoning
- Documentation of discrepancies
- Threshold Achievement
- Target 80-90% alignment with SME
- Iterate until the threshold is met
Production Integration
Once aligned, integrate the evaluation system:
- Set up LangSmith Auto-Evaluation
- Configure expert-vetted prompts
- Monitor evaluation metrics
- Set up alerting for misalignments
Performance Metrics and Evaluation
When evaluating LLM-driven graph creation, we're essentially dealing with a classification task. Understanding the following key metrics is crucial:
- Precision: Accuracy of positive predictions
- Crucial for reducing false positives in entity extraction
- Helps measure hallucination rate
- Recall: Ability to find all relevant entities/relationships
- Important for knowledge completeness
- Helps identify missing information
- ROC-AUC (Receiver Operating Characteristic - Area Under Curve)
- Evaluates model performance across different thresholds
- Useful for comparing different LLM models
- PR-AUC (Precision-Recall - Area Under Curve)
- Particularly valuable for imbalanced datasets
- Better metric when missing data is costly
- Distribution Separation
- Helps understand model confidence
- Identifies potential edge cases
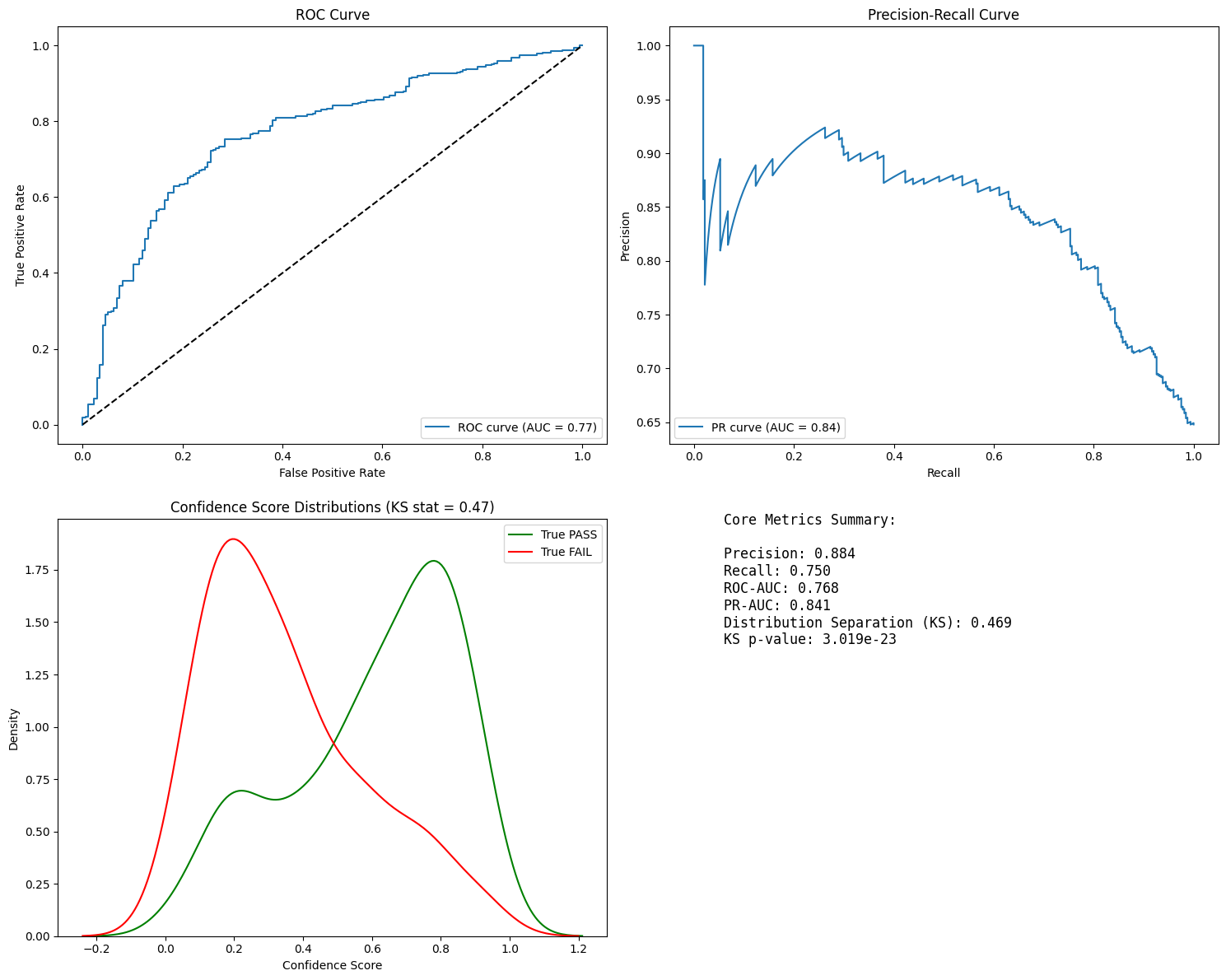
If you use multiple models, metrics can help you to compare each other over time.
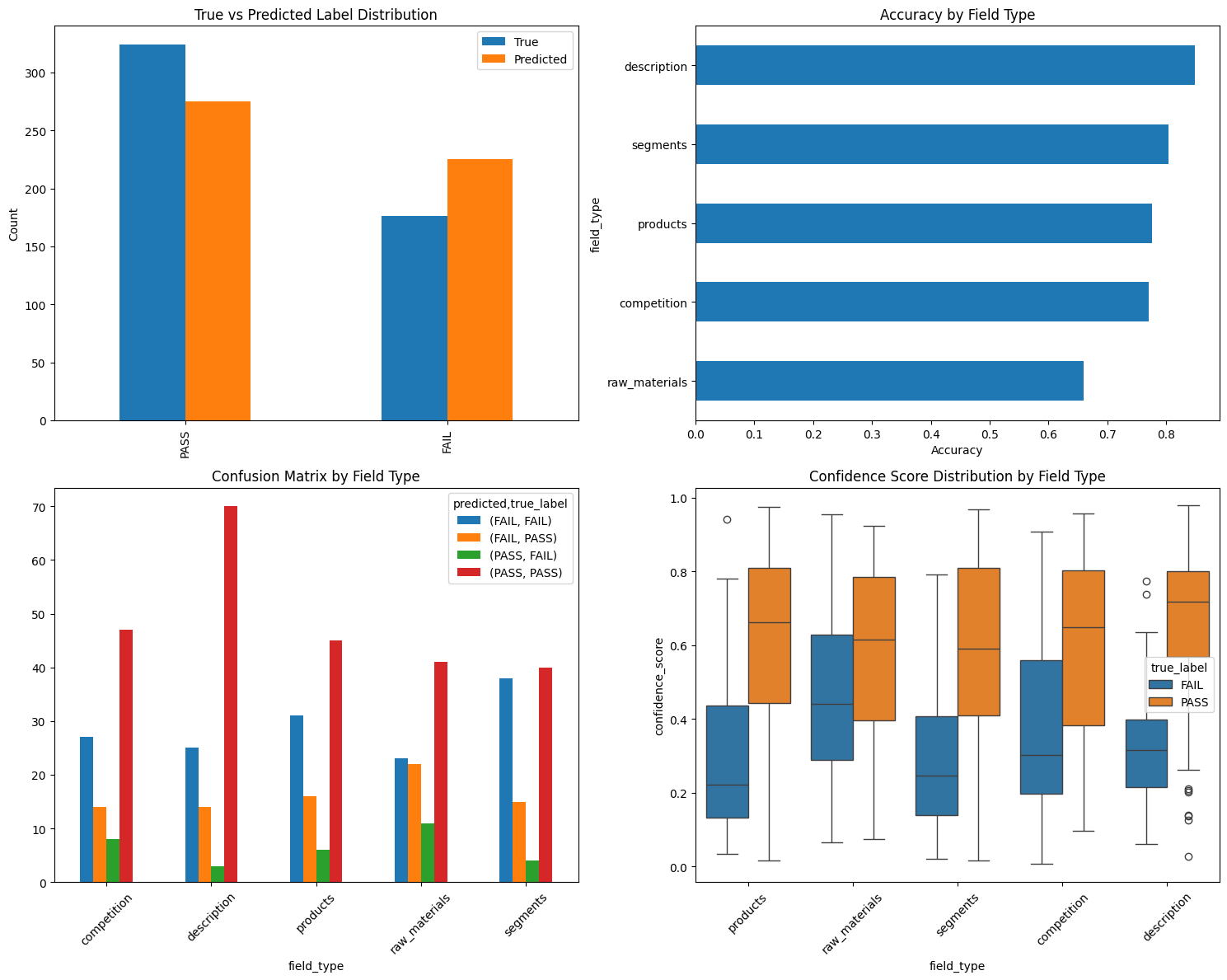
Graph Integration and Quality Assurance
Once confidence in extraction quality is established through metrics, integration with existing graph systems requires careful consideration of several factors:
- Entity Resolution and Deduplication
- Schema conformity
- Versioning & Provenance
- Rollback capability
- Performance evaluation
These metrics provide a quantitative foundation for assessing and improving your graph creation pipeline. With this comprehensive evaluation framework in place, you're well-equipped to build production-grade knowledge graphs.
Conclusion & Summary
Building Knowledge Graphs using Large Language Models opens up exciting possibilities for processing unstructured data, but like any production system, it requires robust evaluation mechanisms. Through this guide, we've explored a practical approach to make your LLM-driven graph creation production-ready:
Key Takeaways
- Structured Approach
- Start with clear ontology definitions
- Collaborate with domain experts
- Focus on specific use cases (like Form 10-K analysis)
- Build incrementally with continuous evaluation
- Evaluation Framework
- Use LLMs as judges with expert alignment
- Implement comprehensive tracing
- Monitor key metrics consistently
- Maintain feedback loops for improvement
- Quality Assurance
- Validate against ontology rules
- Prevent hallucinations through rigorous checking
- Ensure data completeness and accuracy
- Maintain clear versioning and provenance
- Production Readiness
- Integrate robust evaluation pipelines
- Implement entity resolution strategies
- Set up monitoring and alerting
- Enable rollback capabilities
Remember, there's no one-size-fits-all solution. Your evaluation needs will depend on your specific use case, data sensitivity, and accuracy requirements. The key is to start with a basic evaluation framework and iteratively improve it based on real-world feedback and performance metrics.
Next Steps
- Review the accompanying notebook for implementation details
- Start with small, focused evaluations
- Gradually expand your evaluation coverage
- Keep iterating on your prompts and processes
By following these practices, you can build reliable, production-grade knowledge graphs that provide real value while maintaining high quality standards.
References
- Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences by Shreya Shankar et at.
- "We Need Structured Output": Towards User-centered Constraints on Large Language Model Output by Michael Xieyang Liu et al.
- Evaluating the Effectiveness of LLM-Evaluators (aka LLM-as-Judge) by Eugene Yan
- Task-Specific LLM Evals that Do & Don't Work
- Creating a LLM-as-a-Judge That Drives Business Results by Hamel Husain
- Form 10K reports - Jan to September 2024 by John Friedman